Document Infrastructure for the LLM Era
Your AI needs a reliable source of truth, not raw documents.TextIn turns messy, unstructured documents into clean, consistent, AI-ready knowledge — at scale and purpose-built for LLMs, Agents, and RAG systems.
Trusted by more than 1,000 leading companies worldwide
Processed Various Types of Documents
1,000,000,000 +Pages
From raw documents to structuredAI-ready knowledge, instantly.
A unified Document AI infrastructure powering RAG, Agents, and enterprise AI workflows.








Raw Documents




TextIn xParse
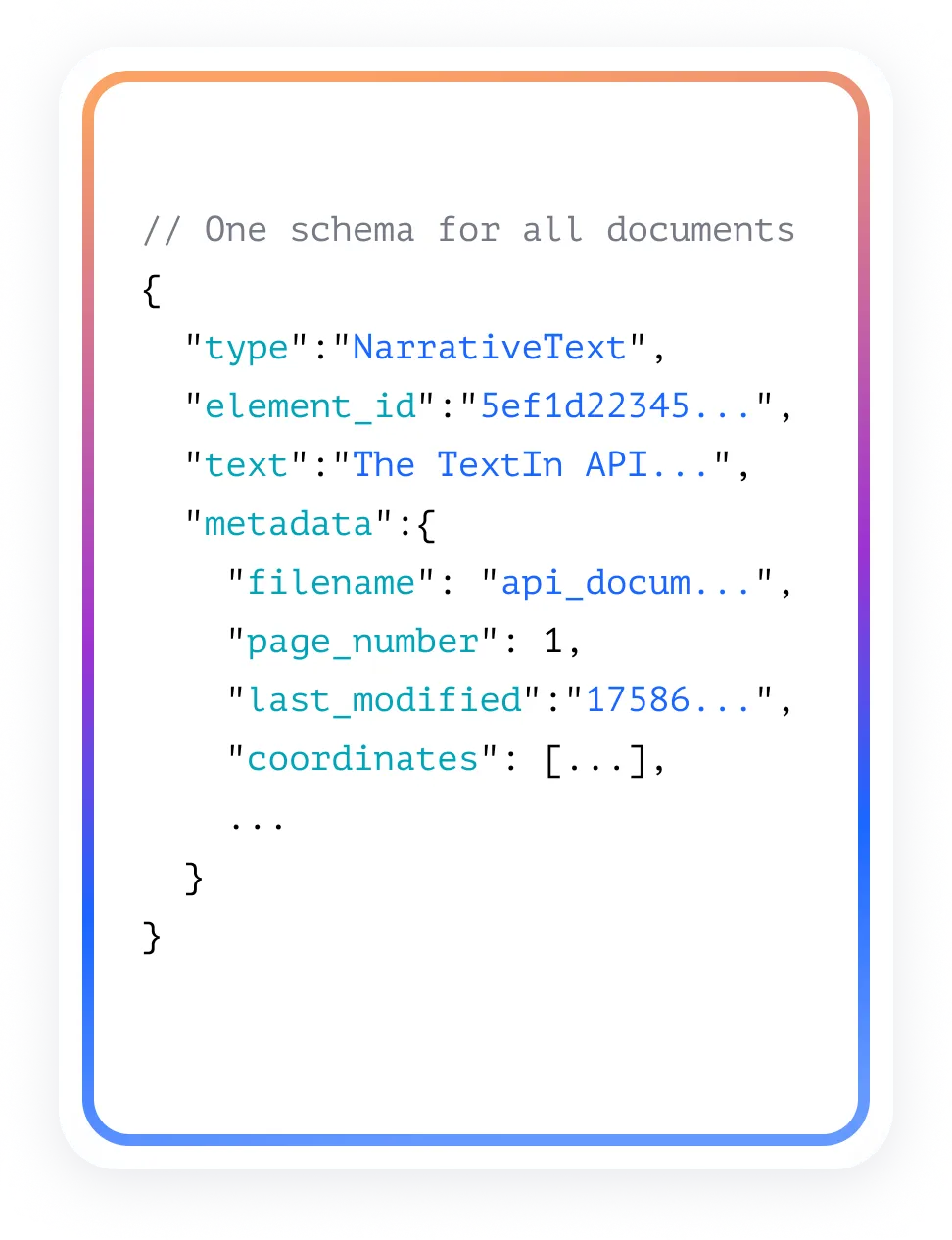
Semantic Chunks

AI-Ready Knowledge
Beyond OCR, Document parsingthat is more user-friendly for large models
High-precision document parsing engine for precise understanding by large models

Break down documents of any layout into semantically complete paragraphs and restore them in reading order, making them more adaptable to large models.
Industry-leading table recognition capabilities easily solve recognition challenges such as merged cells, tables that span multiple pages, and tables with no margins.
Seamlessly integrated with the image processing capabilities of the TextIn platform, it can handle documents with watermarks and curved images.

Make Documents Usable for Every AI
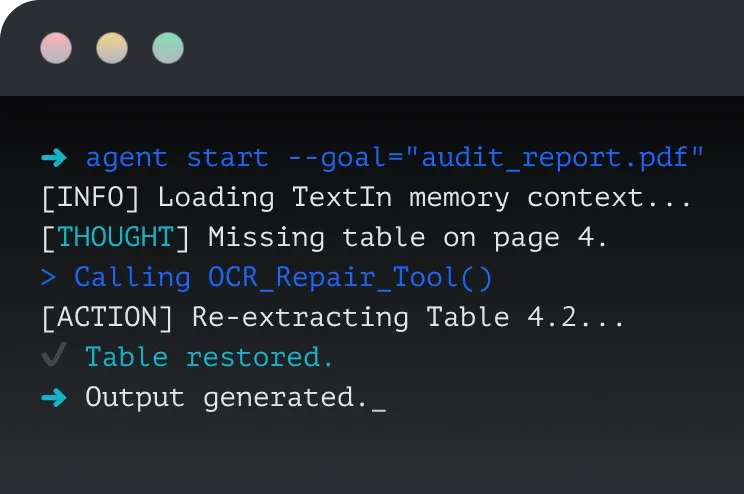
AI creates value only when it can read and use enterprise documents. TextIn turns raw files into reliable knowledge for all AI workflows.
plan
execute
AGENT ERAME
raw file
search_chunk
search_entity
clean data
xParse
fixed table
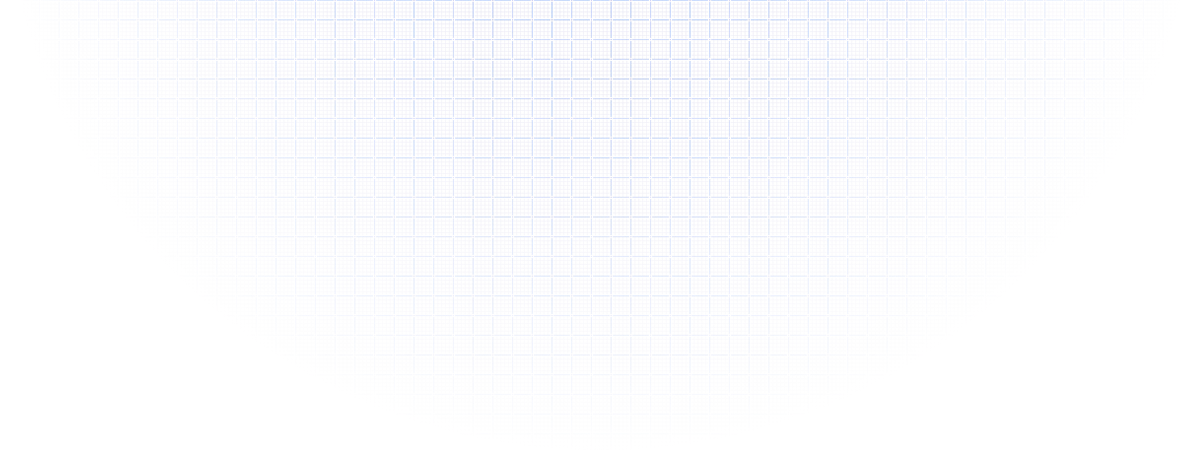
Build Al agents on durable knowledge objects with OCR, chunking, and governance all built-in.
TextIn provided the missing layer between our raw S3 documents and the LLM. From automatic table restoration to metadata injection, we scaled our Agent system in weeks, not months.
PDF
Img
DATA SOURCE
parse
chunk
xParse
VECTOR STORE
Scaling Enterprise Intelligence: An RAG Pipeline for Diverse Pharmaceutical Document Types
Finally, We Can Trust the System": Transforming Complex Regulatory, Clinical, and Research Data into Unified AI Knowledge Access.
User A
User B
Upload Page
index
LLMs
LLM Runtime
xParse
normalize
parse
semantic chunk
Read & Chat Page
Turn any document into LLM-ready input for your
Al Applications
Users just upload a file. Your app hands it to xParse, gets back structured content, and uses it to power Q&A, summarization, translation, rewriting, and more.
User A
User B
Reviewer
Apps
File
class A
class B
class C
...
Schema
A
B
C
...
parse
extract
xParse
K-Vs
...
Validation
Smart Document Extraction Pipeline: Architecting the Shift from Rules to AI-Driven Extraction
We successfully integrate advanced AI Extraction to achieve 90%+ accuracy and eliminate rule maintenance overhead in Financial Operations.
A Unified, Extensible Document Understanding Layer
Plug-and-play. Interchangeable. Future-proof.One integration supports every parsing engine—today and years ahead.
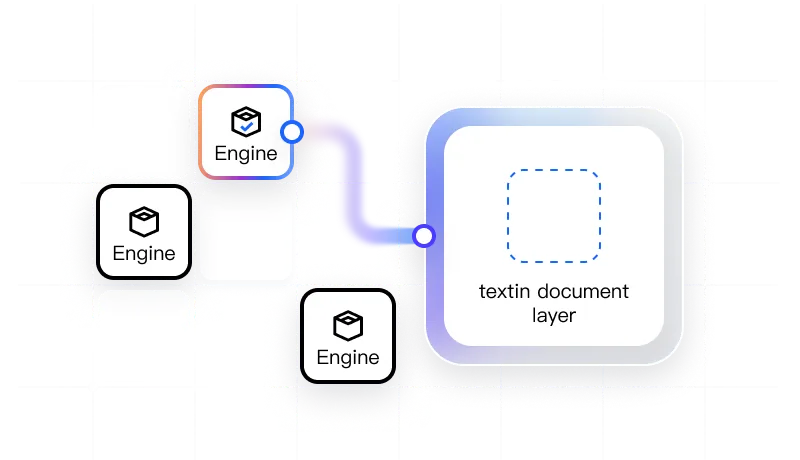
Multi-Engine Routing & Comparison
Support LLMs, OCR engines, open source parsers.
One integration. All engines supported. Fully visualizable performance.

Invoice.png
Receipt.png
VLMs
GPT5
Gemni3
Qwen3
...
OCRs
TextIn
MinerU
PaddleOCR
...

Best Accuracy
0100
Proprietary Image
Enhancement Pipeline
Cleaner inputs. Better outputs.
Turn messy documents into model-ready text.

Future-Proof Plug-In
Architecture
Add or replace engines with zero workflow changes.
Your document understanding never falls behind.
Every Business Document,Accurately Understood by LLMs
From scans and complex tables to system-generated files—everything becomes a unified, LLM-ready output.
PO
SUPPLY
SLA
SERVICE
KYC
FINANCIAL
MoM
OPERATION
RR
RESARCH
RCPT
FINANCIAL
NDA
LEGAL
LA
MEDICAL
CFS
FINANCIAL
P&L
FINANCIAL
Manual
CUSTOMER
BOL
SUPPLY
Unified Parsing →
Structured Knowledge
OCR, cleaning, parsing, and chunking—fully automated. Stable, consistent knowledge objects every time.
16+
Doc Formats
PDFs, scans, tables, PPTs, emails, screenshots—over 16 enterprise formats supported.
Cloud &
Local Data
Connect to OSS, S3, FTP, NAS, and local file systems. Flexible for any enterprise workflow.
Launch Enterprise-GradeAI Workflows—In Minutes
No scripts. No pipelines to stitch together. Upload docs today, get production workflows today.
Old Way: Slow, Fragile, Hard to Scale
 Scripts, rules, crons everywhere
Scripts, rules, crons everywhere OCR, parsing, cleaning, chunking all spread across tools
OCR, parsing, cleaning, chunking all spread across tools Constant glue-code maintenance
Constant glue-code maintenanceNew Way: Fast, Unified, Production-Ready
 One pipeline from raw documents to
business-ready outputs
One pipeline from raw documents to
business-ready outputs Zero maintenance of scripts or crons
Zero maintenance of scripts or crons One SDK to go live with RAG or Agents
One SDK to go live with RAG or AgentsFew Lines of Code, Go Live in Minutes
Upload → auto-structure
→ instantly power business workflows.
Python
Continuously Updated, Always in Sync
TextIn detects changes, parses only what’s new,
and keeps your knowledge and workflows fresh—automatically.
updated
chunks
#
0
1
2
3
4
5
6
7
8
9
A Trusted Foundation for Mission-Critical Workloads
TextIn meets bank-grade security standards and delivers the scale, reliability, and deterministic behavior required for enterprise Document AI.
Security & Compliance
ISO 27001 & ISO 27701
Automatic PII redaction
AES-256 encryption
On-prem support
Deterministic Output
Repeatable, predictable results
Eliminates LLM hallucination
Safe for high-stakes use
Massive-Scale Processing
10M+ pages per day
Elastic scaling for traffic spikes
99.99% API availability
End-to-End Traceability
Chunk-level lineage
Precise BBox grounding
Every transformation auditable and verifiable
Why Developers Choose Us ?
Everything needed to build reliable, accurate AI knowledge systems.
Fighting documents with
“scripts & pipelines”
Thousands of documents. Endless edge cases. Zero visibility.
Shipping
with TextIn Infra
Build & ship AI features — without managing pipelines.
RAG Performance Boost
Cleaner chunks, precise boundaries, consistent metadata, means lower hallucination and higher recall.
<2%
Hallucination
99%
Table accuracy
2x
Recall
Ecosystem-Ready
Drop-in for your existing RAG stack.
Works with LangChain, LlamaIndex, Milvus, Pinecone, Qdrant, pgvector.
Developer-First
No tuning, no pipelines.
A simple API for instant clean chunks.

Don’t Just Take Our Word for It
"We had invested significant resources into developing our own table parsing technology, but its accuracy still fell short of TextIn's solution. After integrating their API, we achieved better performance at a lower overall cost."
Technical Lead
A major financial data provider
"What used to take me most of the day in manual processing now only requires about 30 minutes of verification with TextIn. The speed improvement has been dramatic."
Data Operations Supervisor
A freight logistics company
"Document parsing is foundational to knowledge base systems. After extensive evaluation of available options, TextIn delivered the most reliable and accurate parsing results."
Product Lead
An AI knowledge management company
"TextIn's table recognition capabilities stood out during our assessment. It consistently handles complex table structures with impressive accuracy."
Engineering Specialist
A manufacturing group R&D center
"TextIn's speed in processing long-form documents is remarkable. Even our high-performance internal cluster couldn't match it. This capability is crucial for our real-time Q&A applications."
IT Manager
A financial services company
"Our initial implementation using open-source PDF parsing drew consistent user complaints. After switching to TextIn, we saw a significant reduction in negative feedback."
R&D Lead
An AI technology company
Document Infrastructure for the LLM Era
Make Your LLM Truly Understand Documents
Stop wrestling with PDFs. Start building AI that actually works in production.
Document processing for the next generation.
Legal
Copyright © 2026 TextIn All rights reserved.